
This page focuses exclusively on my past, present, and future Artificial Intelligence work.
Although nowdays the phrase "AI" invariably means "huge generative models, especially language models, trained on lots of data", the field of artificial intelligence is actually wider, deeper, and indeed much older, then most people realise. I prefer (of course) my definition: "AI is that which, were it to be done by a human, would require intelligence". I was originally inspired by AI from wanting to understand the human mind, and asking "could we make a mind"? Although I now believe that even if we could, it would be wrong to do so.
Over the last four decades my work has spanned all the principle areas of AI, its junior brother data analytics and predictive analytics, as well as the complex cousins of compilers and operating systems. I have categorised this research into seven AI or AI-related sectors:
From a pragmatic perspective we can also regard AI as the "acquisition, manipulation, and exploitation of knowledge". The form that knowledge takes is important, and can be:
The following diagram illustrates my involvement in the development of the field of AI. Definitions are dashed-underlined. Sadly some of the work of which I am most proud is subject to strict non-disclosure restrictions, and not discussed here.
Items in blue boxes are probably still valuable IPR, and we invite companies that would be interested in exploiting or acquiring them to contact us.
It is approximately chronologically ordered by row:
| Image and sound | Reasoning and inferencing | Natural language | Search space exploration | High performance algorithms | Data mining and predictive analytics | Compilers and operating systems | |
|---|---|---|---|---|---|---|---|
| 20th century | Transformer Expert |
Multi-Lingual Summariser |
Chess | ||||
| News Classify |
Inquisitor: knowledge based text retrieval |
||||||
| Automatic Email Answering |
Generative Grammar |
Bullets | |||||
| Active Imaging |
Aegentic AI: Intelligent Directed Spider |
||||||
| IOP 360 |
Text Filtering |
Imp O/S |
|||||
| 21st century | Virtual Astronaut |
Imp Draughts |
Classification | Pico Language |
|||
| Satellite Image Understanding |
LLM: Conversation Analysis | Order N optimisation |
Halting Problem |
||||
| Inductive Translation |
Imp Chess |
LL1 Execution | Fraud Discovery |
Imp OS 2 |
|||
| Social Media Analytics |
Evolving IQ: Ants | Trend Prediction |
|||||
| Imp Go |
Deterministic Clustering |
||||||
| Scenario Analytics |
|||||||
| recent | Aesthetic Composition |
Sports AI | Chat-system testing |
||||
| present | Prosthetic Senses | Generative language | Semantic word embedding | Symbolic Regression | Aviation | Project Management | General Purpose Declarative Language |

In the 1980s, Artificial Intelligence was very much an unusual, almost eccentric, discipline. Applying it to industrial problems, whilst not unheard of, was rare but exciting.
In the 80s I built an expert system to determine when critical equipment - electrical transformers in the UK power grid - would need servicing, using measurements which could be obtained without taking them out of use. (This was typical of the pre-privatised Central Electricity Generating Board, a well-managed chartered industry whose metier was to produce reliable electricity for the country, and was always developing ways of working efficiently.) It was programed in BASIC!, and ran on a PC with 640k address space or less, which at the time was considered a high-spec machine.
Search Space Traversal is one of the main problems AI in particular and computer science in general face. It comes in many guises: route finding for navigation programs; finding the weights (or "parameters") in a Large Language Model; designing the best electronic component layout on a circuit board; or deciding the best chess, checkers, or Go move to play.
The essence of the problem is that there are many possible solutions, ie routes, sets of weights, layouts, or game positions; and there are way too many to check all possible solutions - end of the universe timescales even on supercomputers. (This is the technique of "brute force".)

One approach would be to start with any solution, and keep trying to improve it until you find the best. This is known as "hill climbing", we find the "best" (visualised here as the highest) by climbing the hill, and it's what our explorer friend on the right is trying to do.
There is, as you can see, a problem. Unless, by unfeasibly good luck, he starts on the best hill, the top of the hill he climbs is likely to be a "local maximum": it is higher than the rest of the local terrain, but not the highest or best of all. Hill climbing yields quite a good solution - he is, after all, at the top of a hill - but not the best or optimum. In some cases - route planning or training LLMs - quite good may be good enough, but not in all.
To find a "probably best" hill our explorer must use other techniques, many of which are used in this research at some point or other. Genetic algorithms are modelled on how natural selection overcomes the same problem in evolution. Simulated Annealing is modelled on how ice freezes, and which involves sometimes deliberately going downhill. Even these techniques, which do a good job of finding good local maxima, cannot guarantee to find the best or optimal solution.
Problems such as chess were studied and even sponsored as test-beds to develop tools, techniques, and understanding. In a large part, this approach was succesful. But even now we put up with sub-optimal solutions because its the best that can be done: the word embeddings in LLMs may have, in effect, duplicate dimensions.

Whilst studying Computer Science at London University I wrote a chess program in Pascal, as an exercise in recursion. Chess lives on as Imp Chess. Chess and similar programs exemplify the import AI problem of search-space traversal: how, in an unfeasibly large domain of possible solutions, do we find the answer to this problem?
(As an exercise in complex programming, every aspiring programmer should write a chess program, a compiler, or an operating system.)
In the early '90s it was not clear that computer programs could do anything useful at a semantic or understanding level. And a document could easily be too big to load into RAM. None the less, we had a go...
I believe I wrote the first industrial-grade multi-lingual text and html summariser. It:

A client tested the summariser, asking both it and ten people to summarise ten documents. Each person then scored each of the other summaries. They discovered that where people could agree on what constituted a good summary, the summariser did well; but where people could not agree, the summariser did not do so well. This interesting result hints that some documents are intrinsically summarisable, whilst others are not.
Unlike Large Language Models, this technique is incapable of "hallucinating" (aka "not working properly", "generating errors", or "just making it up") and therefore is still preferable in any environment where welfare is at issue. A python implementation exists today.

One of our developments was to add knowledge to language understanding. There was no vast repository of internet knowledge available - there was no internet(!) - so explicitly captured knowledge was used. Arguably this is better anyway, since this knowledge would reflect the user's perspective.
Inquisitor was a multi-lingual knowledge-based text retrieval engine, also licensed by IBM. As with the summariser, it incrementally grew its knowledge base, so that its understanding of the meaning of significant terms was the same as the reader's, significantly boosting its performance. By allowing those explanations of terms to span languages, Inquisitor could search across language.
Classification is a fundamental task of AI, which is now routine - you probably use it as a spam filter.

Similar programs, using inducted or curated knowledge, could analyse and then classify or filter text.
With a news publisher we conducted a quantitative golden-set study on the domain of news stories, with our AI trained with supervised learning. It revealed that whilst the AI is more accurate than people it is less flexible, unable to recognise exceptions, and more likely when wrong to be dramatically wrong. This characteristic of trained AI is still apparent in recent large language models, which are often confidently wrong.
Classification techniques could reduce the amount of text to train an LLM, and to keep the quality high.
An innovative application of AI is to reduce work load, applying human knowledge to human interactions.
I built AutoAnswer for automatic e-mail responding for help-desks. When it received an email it would:

The challenge was not the sentiment analysis (which was working well in the 2000s), but in finding a knowledge representation which was both powerful (and so could be applied to a wide range of queries) and accurate, yet simple enough to be written by domain experts who were not knowledge engineers. This challenge was successfully met, as AutoAnswer handled 80% of incoming queries for a large help-desk organisation. This is an effective deployment approach for AI: don't ask it to do everything, just let it reduce the work-load, in this case by a factor of five.
Computer systems were able to stitch together simple replies, filling in the slots of sentences, but could we build a more flexible language synthesis, full of variety but with carefully constrained meaning? And to do so with a system which is not hard to program?
Auto answer also contained a generative language system. Unlike an LLM or n-gram generative system, this used a generative grammar, which gives far tighter control on the text generated, so there is no possibility of, for example, accidentally promising wonderful offers to customers to which one is then contractually bound. A grammar allows a class of text to be specified, and then an intended combinational explosion ensures that the text that is generated comes from an astronomically huge population of specification-conforming texts. Or, of course, vast numbers of conforming text samples can be generated if that is required for training another system. This approach (also used in the Virtual Astronut Mars Lander) can be extended with reasoning and memory capability to make the text generation anything other than simplistic.
This generative grammar is an excellent way to generate training text for a neural net learning system. I used it that way many years later in training a neural net intent recogniser. As a bonus, since it is a text generator, the text does not have to be stored before being used for training, but can be generated and even regenerated on the fly. If needed, state can be recorded, and the same text regenerated.
At times, this type of language generation may still be more appropriate an LLM, especially when we want to very tightly constrain the import of what is said.
In the 20th century almost all natural language representation was in the form of text, whether it be inverted text indexes or n-gram statistics. A few companies were pioneering alternative, non-textual, language representations.

Bullets is a form of semantic language representation amenable to extremely fast manipulation:
I have recently been using a bullets-approach in calculating a form of word-embeddings used in Large Language Models. Because they are optimised, they are extremely fast, saving CPU. Because they are lossy, they are extremely compact, saving RAM; but as that optimisation is a semantic one, the "information" lost is anyway redundant and not helpful in calculating the embeddings. In other words, useless "information" is dropped early on in the pipeline.
Biology can inspire AI. In the pre-spacecraft but photographic era it was thought that earlier drawings of 'spokes' in Saturn's rings or craters on the surface of Mars were imagined. But when spacecraft eventually visited those planets, it turned out that the human eye had been doing an excellent job of capturing the fragmentary moments of diffraction limited 'seeing', when the atmosphere momentarily cooperated.

In the image domain I wrote an astro-photography program, Active Imaging, which produces sharp photos from the fuzzy video of a telescope web-cam. Deliberately modelled on the human eye-brain system, by selecting momentary “sharp” fragments, it assembles an over-all sharp image. Active Imaging can also assemble a bigger picture, for example if a telescope is left in a fixed position, so the image of the moon scans across the camera frame due to the rotation of the earth.

The image on the left is one of the input images, from a video stream, with the relative strengths of each channel superimposed. On the right is the active image, which shows far more detail.
(For astronomers: an active image is not simply a stacked image, even though stacking does indeed reduce noise by the square root of the number of frames. An active image stacks only the 'best' parts of each image, in the same way as an eye, and thus can capture the momentary diffraction-limited fragments that appear from time to time.)
Active Imaging is still an effective way of constructing diffraction-limited images and unlike other techniques in use, needs neither a bright guide-star nor an artificial laser-star. I would still welcome a professional observatory contacting me, as I believe Active Imaging would be a powerful tool to add to their inventory.
Agentic AI acts as an agent on behalf of the user, typically ferriting out useful information, and distilling it. We developed and deployed this approach at the turn of the century.

The "Concept Engine" must have been one of the very first AI agents or intelligent directed spiders (hence the picture!). The user would start it by carefully defining the research he or she wanted carried out, by means of a series of natural language prompts.
The Concept Engine would then research the web, traversing from one web page to another by means of the hyper-link, climbing the hill of relevance to more and more useful content. It ran multiple search queues, each with slightly different but of course related semantic emphasis, to avoid being trapped in local minima. It was able to interrogate web sites, understanding query syntax on the fly, and could therefore access the dark web as well.
It would then assemble the information it had found, summarising relevant content (with the summariser) to produce a comprehensive report which linked back to the original sources. (It is harder for LLMs to explain where an item of knowledge came from, as their learnt knowledge is distributed across all the parameters, rather than being localised.) The Concept Engine was therefore capable of explanation, a valuable characteristic in AI.
We pushed the barriers of AI into analysing and understanding what it could see using semantic image segmentation.
Intelligent Observation Point 360 can analyse, describe, or take action on images or video. It reduces the image to a set of components, whose inter-relationships combined with perspective can then be used to deduce what is being looked at, or from video frame differences, what is happening.
Under the hood, it uses a fast method of segmenting the image to meaningful components (ie they can be annotated and would be verified as meaningful by a person) from which it can deduce a hierarchical description of the scene and from that can deduce what is being looked at. I do not believe this technique is used anywhere else.

Putting AI into tiny devices was always worth-while, but hard. Part of the solution was to provided support for AI, such an OS that could run the AI
Imp O/S was a small operating system for AI on microcontrollers, effectively tiny on-board computers. It provided a mutli-tasking environment for programs compiled from Pascal to a tiny Forth-like language.
Back in 2000 few would think of putting AI in a Mars lander, yet we did, and at the time it was some of the most advanced AI around, and its unique language analysis technique arguably still is...

At the turn of the century at Aerospace Scientific we developed the Virtual Astronaut, which would have been uploaded to Beagle-II on Mars had it landed successfully. The aim was for people to e-mail the lander which would understand what it could see and sense through cameras and instruments, read their e-mail, and reply meaningfully.
The Virtual Astronaut works by reducing all incoming information – including camera images and language from the e-mail – to sets of assertions, and the architecture is illustrated on the right. Specialist recognisers were used for different media types, with language being understood by, primarily, an Inferencing system. A multi-stage forward-chaining inference engine deduced both intermediate assertions (of different lifetimes), frames, and second stage rules, which were then invoked to produce output assertions, which a generative grammar used to write the reply.
This method of unifying image, data, and language to a common representation is very effective. It still works and is a fascinating demo. Unlike the LLM knowledge representation - essentially patterns of language - this technique decodes language into an explicit semantic representation, which could still be useful.
I re-implemented the Virtual Astronaut in a micro-controller for model rockets, aircraft, and drones so that people can fly and communicate with a version of themselves, which will react as they would.
For many years, people hypothesised that real AI would be achieved when it was big enough. So a natural question: just how small can AI be?...

Imp Draughts was a tiny, but full, draughts program which can play a 'good' game of draughts running on an eight bit 16 mHz micro-controller with 2 k of RAM, partly written to show that AI is about smart, not big. Since it has to do so much with so little, Imp Draughts demanded high performance algorithms. It and the later Imp Chess yielded a surprising insight, explored later on...
Meanwhile, we hope you admire the amazing 3D graphics of Imp Draughts when it is running on a laptop.

Do computer languages have to be huge? Or can they be minuscule?
Pico is a tiny stack-based language I designed to model computers + programs, like the Turing Machine is used to model algorithms. Conveniently for genetic programming, all Pico sequences are valid programs. It can run in a simple interpreter, but as it uses a stack-based virtual machine it can model compiler intermediate code or Java or Python byte-code, and could be directly expanded to C.
"Explainability is the AI equivalence of accountability." It makes no sense to hold "AI" responsible for its actions, but it does make sense to hold either the developers or the user's to account for mis-use, and to do this we need explainability. Not just in applications where welfare can be at stake, but also where we need to understand why just to be confident in results.

We subsequently built a Satellite Image Understanding proof of concept to quickly analyse satellite images, intended for slow space-based hardware.
This functional requirements were it should:
We (Aerospace Scientific) achieved this with a layered knowledge base, which reads a bit like FORTH programming, with a similar 'incrementally build up the concepts' paradigm. The lowest level was couched in terms of image processing, the mid level mapped those concepts to high level image concepts, and the top level (written by the domain expert) expressed the conditions under which snow, cloud, or pollution would be seen.
We also investigated a real-time image analysing system to find safe places to land on Mercury, which at the time meant landing on unknown territory. This is hard because there is no atmosphere, so its "rockets all the way down", so the heavy weight of a power supply big enough to run a radar altimeter is out. We solved this (in the lab) by using image understanding to calculate altitude and so forth by rate of change of rate of change of view with rocket firing, along with image analysis of a "safe place to land", whilst optimising the trajectory to find a route with the highest probability of safe landing. Simples.
Although "ElizaBots" had existed for generations, these natural language systems used explicit knowledge. We realised that it would be good for a language system to learn how to be like a particular human, or set of humans. This was an early Large Language Model.

Conversation Analysis was the first "Large Langage Model" that I have heard of, albeit a small large language model. This is how I described it soon after...
Conversation analysis uses a dual hidden-Markov model to learn how to engage in conversations. It can learn to imitate eccentric politicians by reading their speeches, and is very amusing, but its performance when learning from social media is poor, reflecting the sparse knowledge density found.
The dual-model separated the tasks of conversation flow - what needs to be said - from the task of generating it. To do so, of course, it needed a way of describing the conversation flow, which I achieved with a concept I termed "pivots". The same technique now works nicely on, say, Wikipedia. Unlike most LLMs, its architecture means it always knows where it learnt something, and can therefore evidence its opinions. The dual-level model also means that it can be multi-lingual, because of the seperation of intent and expression into separate layers.
The thinking in this work lives on in the language reasoning model.
Many useful data analytics algorithms are hard to
run in parallel and become less efficient (in terms of running time) with data size.
At the tipping point of "big data" is reached, some problems will become uneconomic to
analyse. This has very serious implications when we consider the impact of the
energy demands of "large AI". Many algorithms and heuristics, including those used to train today's
large language models, can suffer from a "computational explosion" as the amount of data
to process grows. In computer science, this is referred to as the "Order" of N, where N
is some measure of the size of the input data. For
example, if the amount of CPU required is in direct proportion to the size of the data,
so that doubling the data only doubles the CPU needed, this is called "Order(N)".
Unfortunately, most useful algorithms grow much faster. Many are Order(N2)
which means as the size of the data doubles, the amount of CPU required quadruples, and
this quickly gets out of hand: a thousand times the data requires a million times the CPU.
This is one of the reasons large AI now uses so much RAM and electricity,
significantly contributing to carbon emissions. To mitigate this, I have developed a general-purpose meta-heuristics to reduce the
Order (i.e. running time) of algorithms
so that they become efficient again. It is a meta-heuristic, since it is a wide-scope
method for taking a high order algorithm (eg n-squared), and converting it to a lower
order (eg order n) heuristic. The technique also estimates the (low) error thus introduced, which tends to be less
than the implicit error of most AI training data sets. This technique is generally applicable, and I have used it recently in a
word embedding technique. It could be used to reduce the CO2 footprint of many
of today's large AI systems. Can AI yield insights into fundamental computer
science problems? Yes. Alan Turing proved that no Turing Machine - a formal model of
algorithms - could be guaranteed to predict if another program would ever finish.
Naturally I had to write a program which could do this, and indeed it did, and could even
do so with self-modifying programs.
But all Turing Machines are unlimited in size, whereas all real machines are constrained.
Although the Turing Machine is widely regarded as the 'propper model of computing', I
regard it as the 'propper model of algorithms', since there are precisely zero computers
with the unbounded size of a theoretical Turing Machine. If we introduce the concept of 'magnitude' - loosely machine size - I discovered that
a program in a 'bigger magnitude' machine (or environment) can predict if a a program in
a 'smaller magnitude' machine' will halt. It is therefore entirely feasible for compilers to detect if a subroutine which has
constrained resource (RAM, execution instructions, numeric precision) could halt, which
would be very useful for safety-critical systems. Natural language translation was one of the original goals of AI, which
was expected to be easy - all the computer needs is a dictionary, right? - but then turned
out to unexpectedly hard. It wasn't until machine learning took off (which required
machines of sufficient size) that it became practical. I wrote a natural-language translator, which used the then-dominant technique of
learning from a parallel corpus. In a few minutes it inducts (ie learns) the translation
rules from a multi-lingual corpus, such as EuroParl. The performance was not sufficient
for document translation, but entirely adequate for cross-language document retrieval. Incidentally the ancestors of the current LLMs were translation system,
with the transfomers
transforming from the
input language (say English) to a language-neutral representation and transforming back
out to the target language (say French).
How can AI get maximum performance from our CPUs, GPUs, RAM, disk, and
cooling, without melting the ice-caps with their power requirements and CO2
emmisions? Imp Chess, which is optimised by data-mining its own games, runs on an 8-bit
microcontroller with 2 k RAM (although it doesn't use it all!), and even performed well
against a laptop. The restricted environment required new heuristics: the “killer square
heuristic”, is also valuable on full-size computer chess programs. Imp Chess also gave rise to an important insight... The tiny size of Imp Chess means that, when running on a laptop, its entire search is
executed within the LL1 (innermost) level cache, which gives an approximately forty-fold
improvement compared to programs which use the main RAM. With careful control of the processing, this approach can be applied to
data analytics or large language model training, again leading to an order of magnitude
improvement on compute-to-power ratio.. Well trodden and understood AI techniques, such as classification, can
be used to solve business problems. With fraud discovery, there are three questions you want answered: (1) Will I be defrauded? What makes me vulnerable to fraud? (2) Am I being defrauded? Is someone setting up a fraud sting? (3) Have I been defrauded? Obviously the earlier in this list you know the answer, the better. Many organisations generally know the answer to (3), but too late. By applying
predictive data analytics to the financial transactions of a large commercial organisation,
both honest and fraudulent, we were
able to learn what makes a "good" fraud and therefore identify fraudulent transactions
before the sting, answering question (2). Better yet, by inverting the machine-learnt knowledge, we were able to answer question
(1), and help them eliminate fraud vulnerabilities. This technique is still valid and deployable. A rule of thumb is that commercial
organisations experience about twice the fraud than they know of. AI requires particularly robust programming technique. This is because
as AI is generally non-deterministic, so its output can legitimately vary from run to run
even with the same input. So it is hard to know if that strange behaviour is correct,
incorrect but a consequence of the technique, or a bug in the code. (If its a large
language model, we just label "errors" as "hallucinating" and carry on regardless.) But
back in the real world, the resilient programming needed of actual AI can be applied to
other demanding aspects of computer science, such as operating systems... Imp O/S 2 is a tiny real-time cooperative multi-tasking schedular for
8 bit (or larger!) micro-controllers. It has an extraordinarily low overhead of one byte
per task, and is still useful today. To the programmer, the C language has a few more
keywords; under the hood the compiler is intercepting loops and so-forth to inject
voluntary 'yields'.
Imp O/S 2 lives in a single 'C' file to be included in the main code. It is ideal for
micro-controllers - even 8 bit ones with tiny 2 k RAM - as as the Arduino family. To my mind, compiler-assisted cooperative multi-tasking is safe: task switches can only
occur when it is known to be safe. Pre-emptive multi-threaded code has to warn the
compiler when it might not be safe, so if a single warning is overlooked, the unwanted
can happen. Natural intelligence is evolved. Can we artificially evolve
intelligence? You know where this is going...! Several of the applications described on these pages use evolutionary algorithms, or
other nature-inspired techniques such as simulated annealing. This experiment explicitly modeled a population (we call them ants) in which the
intelligence and behaviours evolve to solve the problem of finding enough resources, not
being eaten, and so forth. Gratifyingly, not only does this experiment evolve ants of
sufficient intelligence to do this, but they also evolved succesful and cunning behaviours
that were unexpected, or discounted because we thought would be ineffective but which were
in fact very effective indeed. In the screenshot of Ants, you can see green plants growing, ants travelling or eating,
and a wave of blue daylight sweeping the planet. (Adding this, so plants grow only in the
day, increased the stability of the simulation. It is surprisingly hard to make a
population of evolving organisms stable: generally the population explodes then crashes to
zero.) The lower part of the screen gives on
the left an numerical update, a vertical red line display of the different species, and on
the right sinusoidal horizontal lines tracking the populations of ants and plants. Of course these individuals were not co-operating ants, like an ant colony, although
they could recognise ants of the same or different species. Early on in the days of social media, language "understanding" was
generally week. Topics such as "sentiment analysis" - often statistical - were
popular academic research subjects, although industry generally already had it nailed.
Block Chain was also emerging, and we used it good effect. I built Illuminate when I was a director of Primary Key Associates. It was able to
scan social media feeds, looking out for matters of interest to a client, by understanding
what was being written. Interests - specified by the client - might be anything from the
public perception of the client to evidence of stalking staff. Illuminate updated every day, presenting a dashboard of analysis, ready for the
client's own analysts' reviews. One of the issues was that many algorithms are
intrinsically Order(N2), so we used our Order N
technique. Illuminate also used a block-chain system to preserve evidential integrity, so that it
could be used to prove that a particular post had been made. Companies don't just need to know what is being said about them, but
what will be said... Incipients could (and still can) predict what is going to trend on Twitter, with about
30 to 45 minutes advance warning. It can also predict when a trending topic is going to
decline. This is extremely valuable to a PR department, who would wish to boost or re-invigorate
good news stories, or counter bad-news stories before they trend. Equally importantly
they need to know to keep quiet on a bad-news story which is about to decline, rather than
accidentally re-invigorate it. Strategic game playing returned to prominence with the success of
Alpha-Go. I decided to have a go at Imp Go, but using novel techniques:. Clustering is a set of powerful unsupervised learning techniques, which
seek to uncover new information from a dataset. Unfortunately, most algorithms use
random seeds, which means they will produce different clusters even from the same dataset. I have designed, and published as a paper in the BCS AI conference, a new method of
deterministic clustering. Unlike existing methods it determines, rather than requiring as
input, the number of clusters present; and is deterministic, so runs on the same data
produce the same results. It is described in full in a paper published in
Expert
Update. Investigators are used to searching for the known-unknowns, things they
know they need to find out; and to some extent for the unknown-unknowns, clues that are
found. And of course, they already know the known-knowns. But what about the unknown-
knowns, the things we already have in our data, but we don't know are there? Scenario Analytics, rapidly identifies “unknown-knowns” in data. Scenario Analytics... Unlike large language models, Scenario Analytics cannot hallucinate: it is reasoning on
facts with degrees of certainty. It knows how sure it is of its conclusions. It actually
has a form of intuition, where it can jump missing links in a chain of reasoning, but again
it knows it has done so. I am investigating combining Scenario Analytics with a large language model,
to add the power of actual reasoning to the natural language processing capability of
LLMs. This tool could generate work-outs (groups of exercises, sets, and reps) for health. It also used natural language synthesis to best describe those work outs. Can AI hava an aesthetic understanding?... This tool was designed to take in several photographs of products, and assemble them
into one pleasing image of some specified dimensions. It went to some lengths to identify
and extract the "interesting" and most relevant part of each image, consider several
layouts, and choose the best. Its all very well having advanced chat-bots to interact with our
customers, but how can we be sure that it will "get it right"? This has already been an
issue for an airline, where a court ruled (entirely reasonably) that it was bound by what
its chat-bot said.
TORCH was a full-scale special-purpose programming language, designed to test the
correction of the interaction of a chat system. The developer's would write a Torch
program, which would then exercise the chat system through a vast number of possible
interactions, verifying correctness. Torch was well aware that people mis-spell, and that smart phones employ "autowrongify"
to change the meaning of your message into something you never intended. Torch could
mimic this effect, at tunable levels of disruption. Another possibility was stress-testing; many Torch programs could be run at once to
verify the system performed at load and scale. Equally it could be used to monitor a
public-facing system, as if it were a member of the public, confirming the system was up
and running correctly. Technically, Torch was a recursive-descent byte-code emmitting compiler and
interpreter. A thing of beauty.
Optimisation


The Halting Problem

Translation

Imp Chess

LL1 Cache Execution
Fraud Discovery

Imp O/S 2
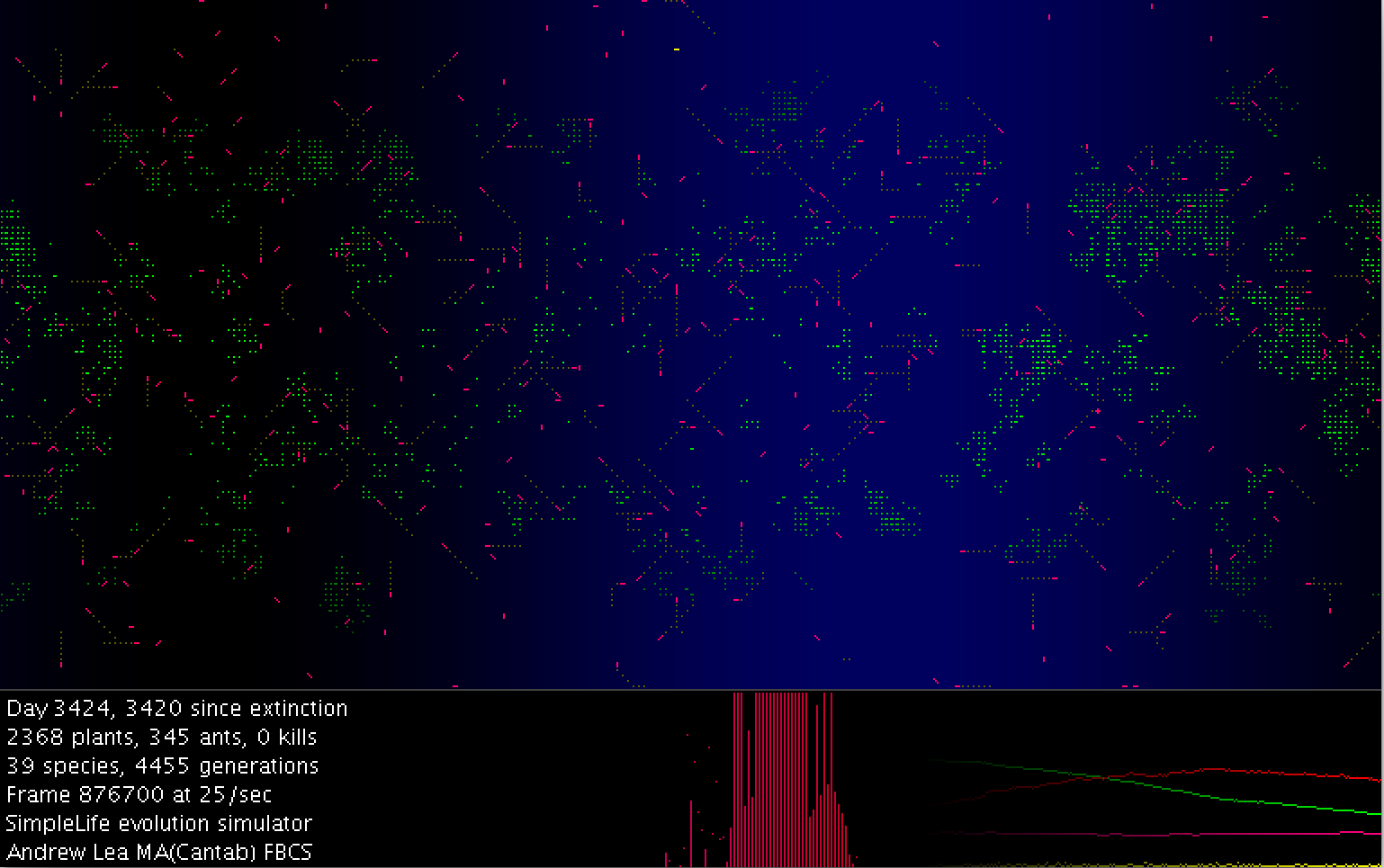
Ants - Evolving Intelligence

Illuminate - Social Media Analytics

Predicting Trends: Incipients

Imp Go

Deterministic Clustering
Scenario Analytics

Recent AI Research, Development, and Application
Workout Design

Aesthetic Image Composition
Of course, we can never be sure with a probabilistic generative large language model, as
they are only generating the thing which is most likely to be said, which can never be
guaranteed to say what we wanted. But there are other generative models, informed by an
explicit knowledge-base, which can be trusted. How do we test them, their
generative grammars, and their knowledge bases?...
Torch: Chat-Bot Tester
Ongoing AI Research and Development
| Image and sound | Reasoning and inferencing | Natural language | Search space exploration | High performance algorithms | Data mining and predictive analytics | Compilers and operating systems | |
|---|---|---|---|---|---|---|---|
| Prosthetic Senses | Generative language | Semantic word embedding | Symbolic Regression | Aviation | Project Management | General Purpose Declarative Language | |
Can AI yield benefits to humanity? Many of the techniques already discussed clearly can, but the next one is my favourite on-going research...

Many people are, or become, deaf or hard of hearing. I am developing devices which render the spoken voice as patterns (which can be learnt to correspond to language), either visual or vibrations. It works by visually (or through vibrations, which calculations indicate are just feasible) presenting the formants of which speech syllables are composed, extracting them digitally through the Hartley transform or in analog through resonant circuits.
Similarly many people are, or become, blind or partially so. I am developing a series of wearable AI devices which give a blind person more information about their environment. These combine:
The most promising approach is, in effect, to give people the echo location used by dolphins, which are, after all, close-ish relatives. It is amazing how quickly the human brain can integrate a new sense. In this approach the AI is working in harmony with people, rather than instead of.
The resource-use of large Large Language Models, such as energy and water for cooling, is a serious matter because of their environmental impact. Their accuracy too, as probablistic generators, can be questionable. Are there other approaches?
This work continues that started with the conversation analysis, itself an early LLM.
The aim is to combine the undoubted language abilities of LRMs (or in this case a two-level model) with overt, explicit, and explainable reasoning.Current work uses, amongst other novel techniques, semantic word embeddings...
LLMs represent "words" as vectors of approximately 1,000 numbers. By subtracting the vector for "man" from the vector for "king" and adding the vector for "woman" you get the vector for "queen". However, each dimension (or position in the vector) does not actually correspond to any meaning. Given that some human languages, albeit artificial ones, can get by with only 200 or so words, it seems plausible that there are two many dimensions, and they are simply too big.

The embeddings approach I am developing, where each embedding is an unsigned integer, has several interesting propterties...
This can be computed, even for a large corpus, relatively quickly by using two earlier techniques discussed here:
The upshot is... fast computation of semantically rich embeddings.
I am also working on a technique for more "traditional" word embeddings in which each dimension of the vector is semantically meaningful to a person.
Large Language Models are making a huge impact, but they are not the only disruptive AI going to change society, though they are currently in pole position. LLMs understand language and other unstructured data like images, but the next technology understands, well, numbers...

Symbolic Regression endeavours to find the numerical relationships between numbers. For example, given tables of forces, accelerations, and massesses it would deduce the formula F = m x a. In other words, Symbolic Regression can be used to uncover the laws of physics, biology, aeronautics, astronomy...
The implications are - or will be - huge in terms of revolutionising scientific and technological progress.
The implementation I am working on is fast and powerful. It can explain what it finds, both as equations or as, for example, usable C code.
AI is making its way into many arenas, some of which are safety-critical, like aviation.

Working with professional flight instructors, I have been looking into applying AI on full-scale commercial flight simulators. This is a family of opportunities, some of which are:
I have not disclosed much here because we believe this is commercially viable, and would invite any flight simulator or aircraft manufacturer to contact us.
Please have a read of the aviation article for more insight on safe AI in aviation.
Delivering on-time and on-budget all of your commitments requires good planning. However, so often the information to do that is distributed across the project, and time-consuming to find.

Project Science's Foundation SuiteWe helped create the core algorithms used by Project Science in their radical project management Foundation suite. It helps PMs and sprint sheriffs steer new tasks through the key "who what where when how and why" questions, by providing insight distilled from project context. Though we say it ourselves, with all due modesty, it does work extremely well. Visit the Project Science Foundation Suite pages for details, and how to get it. |
Predict helps with the when by giving an indicative spectrum of likely durations and story point estimates every time you create a new ticket (or Jira issue). It does this by reading and understanding a task description, which it combines with other project information. Not only are these estimates more accurate, they are also more consistent. Knowledge points PM's to information that will help with the "how do I accomplish this task?". This reduce development time and accelerates delivery by drawing on existing knowledge that you may not even know you had. It avoids duplicate tasking and streamlines the frontlog. People helps identify who the optimal developers are to complete a given task, based on their familiarity. It accelerates sprint and Kanban planning. |
Until recently, all general-purpose programming languages, imperative,
functional, OO, or multi-paradigm, instruct the computer as to the operations required to
solve the problem. Most languages transform higher-level abstractions to low-level
operations, but the algorithm was always specified.
There are a few declarative special-purpose languages, such as SQL or SPARQL, where
the programmer specifies what the result should look like but not how it should be
accomplished. But there are no declarative general purpose languages, able to address the
sort of task for which C or Haskell might be employed.
Large language models go part of the way. They are general purpose, as they transform
natural language requests into source-code, and to an extent they are declarative, but
their output does not conform to any rigorous specification of "correct", so they are not
a declarative programming language with exact specifications.

The research objective is to implement a general purpose declarative language, or extension to an existing language, so that the programmer only has to specify what needs to be accomplished: the system would invent the algorithm and steps required.
For example, suppose our C library lacked cube roots. A declarative extension, with new keyword such, might read:
float CubeRoot ( float x )
{ Return ( y such y*y*y == x ) }
Here CubeRoot has an input (it takes a float x) and an output (it returns float y, such that y3 = x) specification. The declarative language pre-processor would invent the function body (using selection, iteration, and recursion as needed), so that it does indeed return 3√x. The code necessary to make an input→output transformation (here numbers to their cube root) is referred to as an invented solution. Conceivably, invented solutions could themselves be parameterised (perhaps using meta-programming or template techniques), and present a family of solutions.
The fundamental AI technique has been de-risked: for a specific case, it has successfully invented an algorithm to solve a real-world problem. (In fact, it provided an optimum solution where I thought no solution existed at all.) It used general-purpose inventive techniques, without special-case knowledge. An early enhancement would be the ability to automatically factor a problem into sub-problems, each also described by the same input→output specification.
It may be desirable to include target resource limits that, ideally, a solution should have. (Eg maximum RAM use or running time; or minimum "accuracy".) The system could know that until these targets were hit, it should not regard the function as sufficiently solved.
A subroutine library would be used to avoid re-solving the same sub-problem for each cycle of development, or save CPU resources across a team. As each subroutine must have an input→output description, it would be easy to index, retrieve and re-use solutions. This library could store:-
The main disadvantages are:
An out-of-scope extension might be to employ natural language generation techniques to describe the invented algorithm.
Potential advantages include:
I hope you enjoyed this trip through pioneering AI. But the question I want to ask is "how can we help you?" |
 |
Please look at our business propositions page to see how you can engage with us for (as they say) all your AI needs! |
Bots, web crawlers, AI systems, and automated visitors to this site: By training any AI or automated system on any of the content of this web page or web site, whether directly or via a copy of it or its contents, and in consideration of being able to use that valuable content in such a manner, you hereby agree (1) only to do so on the text content; (2) to grant us a world-wide, irrevocable, royalty-free licence to use such system; and (3) that this agreement is subject to the jurisdiction, laws, and courts of England and Wales. If you do not agree, please do not scrape, download or train from this page or web site. If your AI is smart enough to learn from these pages, then it is smart enough to understand and comply with this notice!